Es práctica común en cualquier “experiencia paranormal” el fiarse de los sentidos, y de la interpretación que se da de esa percepción. En especial casos de OVNIs, caras de Bélmez (R), o psicofonías. Si pensamos en el cuerpo humano como una máquina, el oído o la vista son sus sensores, su medio para comunicarse y saber que ocurre en el mundo exterior, y transmitir información de éste a un centro de procesamiento (el cerebro) donde se interpreta esta información.
Sin embargo, estos sensores naturales tienen una calidad determinada; suficiente para vivir en el mundo que nos rodea sin muchos problemas, pero limitada al fin y al cabo:
Sin embargo, estos sensores naturales tienen una calidad determinada; suficiente para vivir en el mundo que nos rodea sin muchos problemas, pero limitada al fin y al cabo:
La vista apenas da para detectar un rango ínfimo de longitudes de onda de luz (400 a 800 nanómetros). El oído de igual forma, sólo puede recibir ondas de presión de determinada frecuencia (20 hz a 20 Khz). No solo el rango está limitado, sino también las intensidades mínimas y máximas que se pueden distinguir tanto de luz como de sonido. Por debajo del mínimo, nuestros sensores no captan nada. Por encima del máximo, hay una saturación que puede provocar daños en nuestros órganos sensoriales. Y para rematar, y como todo sensor que se precie, tienen una resolución limitada. Es decir, un ojo llega un momento en que no puede distinguir dos fuentes de luz demasiado cercanas, ni puede distinguir dos ondas de frecuencia muy parecida, ni tampoco distinguir dos pulsos de luz separados por un intervalo temporal muy pequeño. Al igual que el oído, que tiene problemas en distinguir frecuencias de sonido muy próximas, o sonidos separados por un lapso de tiempo muy pequeño.
Lo mismo ocurre con el cerebro. Tiene unas capacidades limitadas que hace que las interpretaciones de las señales que nos envían los sentidos (y sus limitaciones) sean a veces erróneas.
Hay cantidad de webs que muestran ilusiones ópticas, de muy diverso tipo: falsa percepción de colores, falsa percepción de movimiento, lograr ver una imagen en 3D a partir de imágenes bidimensionales o falsa percepción de figuras reconocibles a partir de manchas aleatorias.
De igual forma, un oído puede sentir falsas percepciones en cuanto a si un sonido sube o baja de frecuencia, si es intermitente, e incluso puede llegar a escuchar palabras donde solo hay unos sonidos sin un sentido concreto.
Y con esta larga introducción, llegamos por fin a la pareidolia.
¿Cómo demostrar a alguien que una percepción es fruto de la pareidolia? En teoría, debería ser fácil hacer ver que manchas que se interpretan como una cara con sólo eso: manchas. Un poco más complicado parece demostrar que una “acongojante psicofonía” corresponde a un sonido que nada tiene que ver con una voz.
Una cara, o una voz tienen unas características específicas. Si se parametrizan, debería ser posible comparar entre la presunta cara o voz paranormales, y una cara o voz real. Olvidándonos ya de las caras, y metiéndonos más específicamente con las voces y las psicofonías, el sonido de una voz tiene una estructura que depende de la forma en que se produce, y que afortunadamente es igual para todo el mundo. Es decir, todos realizamos los mismos movimientos para producir los mismos fonemas. “Sólo” cambian unos pocos parámetros, pero que permiten tener una amplia gama de matices que nos hace distinguir a unas personas de otras.
La voz se genera con una combinación varios factores. El primero es la presión de salida del aire desde los pulmones. Al llegar a las cuerdas vocales, éstas generan unas vibraciones. Por si alguien se no acuerda de lo que decía la malvada ciencia oficial acerca de las ondas, recordemos que una cuerda de una longitud fija, sólo puede vibrar en un conjunto discreto de frecuencias: a una determinada frecuencia fundamental F0, y todos sus armónicos , es decir, múltiplos enteros de esta frecuencia (2F0,3F0. 4F0…). Simplificando un poco, esto mismo pasa en las cuerdas vocales. Esta frecuencia depende de cada persona, está alrededor de 125 hz para hombres, 250 hz para mujeres, y 350 hz para niños. De esta forma, de las cuerdas vocales sale un sonido consistente en una frecuencia fundamental, y sus armónicos, con amplitudes cada vez menores.
Si sólo este aparato interviniera en el habla, nos diríamos cosas muy aburridas. Tan sólo emitiríamos tonos, con las leves diferencias de aplicar una presión de aire distinta a la entrada de las cuerdas vocales. El elemento que nos falta para generar los fonemas y todos los sonidos que puede hacer una persona, es una caja de resonancia. Al igual que en una guitarra, o cualquier instrumento musical, esta caja enfatiza unos armónicos, en detrimento de otros, y cuales enfatice y cuales atenúa depende mucho de la forma de esta caja, de forma que es la responsable de todos la generación de sonidos, y de los distintos matices que se dan entre voces de distintas personas. Se podría decir que hablar no es muy diferente de tocar la guitarra.
Esta caja está compuesta por la cavidad bucal, la nasal y la lengua. La boca más o menos abierta, la posición de la lengua, si el sonido se va parte por la nariz, o si está taponada por un trancazo de caballo… son un sinfín de matices que determinan el timbre de una voz, y que distinguen a una persona de otra, e incluso denotan si hay alguna anomalía.

Habíamos dicho que a estas cavidades llega un sonido monótono, consistente en una frecuencia fundamental y sus armónicos. La cavidad, según la forma que se le de con los músculos de labios, mofletes o la lengua, va a tener un “espectro de resonancia" que va a “modular” el espectro de sonido entrante, de forma que en el sonido final que sale de la boca se van a reconocer rangos de frecuencias, que vienen a llamarse formantes.

De esta forma, se ve que la voz tiene una estructura específica. Cada fonema de hecho, emitido por la persona que sea, va a tener una estructura general que va a ser la misma. Tan sólo en las leves diferencias en frecuencia fundamental, o pequeñas variaciones en la cavidad resonante van a dar el matiz para diferenciar entre una a dicha por mí, de una a dicha por otra persona.
La fonética, y su representación en espectros es mucho más complicada que lo que aquí se está resumiendo. He hablado de lo que sería un sonido armónico como el de una vocal, pero hay fonemas que no presentan espectros de armónicos, sino que son (literalmente) explosiones, aire expulsado como alta presión (las consonantes p, t, b, por ejemplo), pero que puede ser igualmente caracterizado.
Y así, llegamos a una situación en que un experto podría parametrizar de forma objetiva una voz. Y una vez hecho esto, se puede llegar a comparar con el sonido de una psicofonía. Hay formas más o menos rigurosas de hacerlo. Aquí, que no somos expertos en acústica ni fonética, sólo podemos optar a una comparación “a ojo”, que dentro de la subjetividad que implica, puede ser de ayuda para ver por donde van los tiros.
Afortunadamente hay psicofonías suficientes en la red para poder juguetear con ellas, y más afortunadamente todavía, hay alguna en la que el propio autor se graba haciendo la típica pregunta que se supone hay que hacer para que responda una psicofonía. Eso nos ahorra sentirnos tontos hablándole a un micrófono para poder tener una voz real que analizar someramente.
Esta psicofonía en concreto que vamos a ver, se encuentra en un artículo de MundoParapsicológico. Se escucha al autor preguntando “¿Cuál es tu nombre?”, y cómo claramente le contestan… eh.... bueno... En realidad, se escucha un ruidillo. El autor dice que contesta “El de un mensajero”
Bien, pues yendo por partes, he aquí el espectro de la pregunta ¿Cuál es tu nombre?
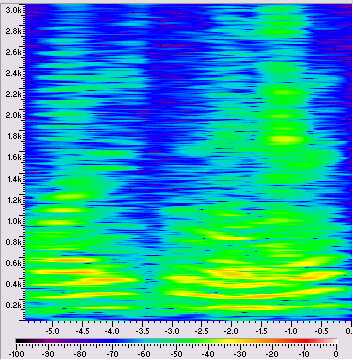
Estos gráficos representan en el eje x el tiempo, en el eje y la frecuencia, y en código de colores la intensidad. De esta forma, se ve la evolución temporal de cada una de las frecuencias que componen el sonido. Los colores indican la intensidad de esa frecuencia, en ese instante de tiempo , siendo azul el mínimo y rojo el máximo(y entre medias, el verde y amarillo). En este espectro se ve muy bien cómo se forman bandas horizontales: estas son las frecuencias que vienen de las cuerdas vocales, y cómo desaparecen cuando se cambia de fonema, para volver a aparecer luego cuando se pronuncia otro distinto. Si nos fijamos en un punto concreto (la u de cual), podemos ver el espectro en forma de gráfica:

En el eje x tenemos frecuencia, y en el eje y intensidad. Se ven muy bien cómo los armónicos están separados a distancias fijas (algo más de 100 hz, que correspondería a la frecuencia principal), y pintados en azul se ve “grupos de frecuencias" a 500, 1000 y 2000 hz, que son los formantes.
Vamos ahora con la psicofonía. Su espectro de frecuencia y tiempo:

Donde lo único notable son dos bandas horizontales amarillas al principio, y alguna más hacia el final. No hay estructura de armónicos, ni de formantes. Si nos fijamos en alguno de esos dos puntos llamativos, sus espectros tienen estas formas. Del principio de la psicofonía:
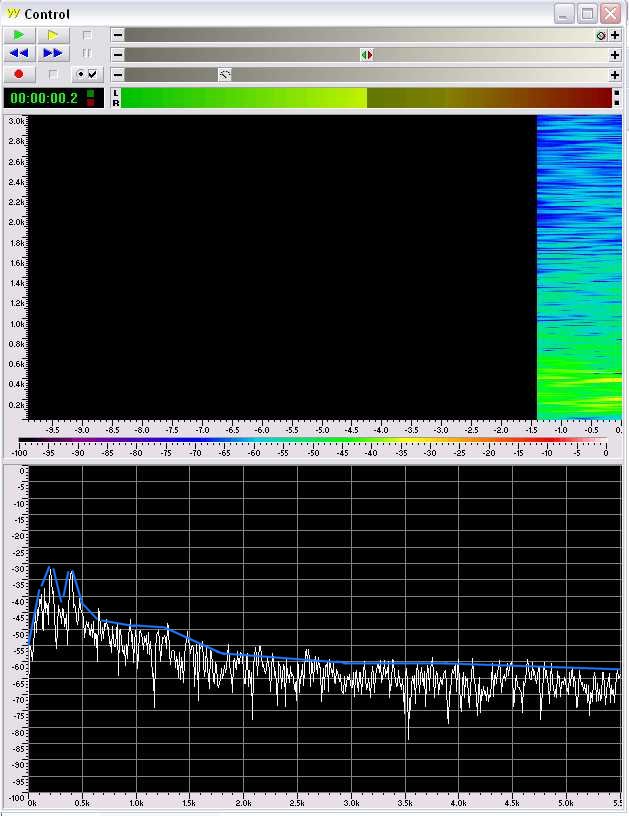
Las dos bandas, alrededor de 300 y 500 hz, no son armónicas ni entre ellas, y además falta una estructura de formantes.
Y del final de la psicofonía:

Ocurre lo mismo: dos picos, uno sobre los 200 hz, otro con atisbo de estructura a 500 hz, y ruido.
Se puede argumentar que el ruido es demasiado alto como para dejar que aparezcan los formantes, y están ocultos en él. Sin embargo, si volvemos al sonido de la palabra “cual”, se puede ver como los formantes caen 10 dB en amplitud uno respecto al otro. En el caso de la psicofonía, las dos frecuencias que sí aparecen, sobresalen del ruido en unos 20 dBs. Es margen suficiente para que al menos asomara el segundo formante, a pesar de las pequeñas diferencias que pueda haber entre hablantes distintos.
En resumen
Toda esta parrafada que nos hemos marcado es para intentar mostrar de una manera un poco objetiva cómo hay sonidos que pueden parecer voces, pero que observados con atención, resultan no tener la estructura propia de una voz. Se podría considerar pareidolia. Oro parece, plátano es.
Aún sin saber el origen de esos ruidos, que pueden ser mil distintos, todos mundanos, y que se confunden con oro, una prueba de comparación (con más o menos rigor) así debería ser suficiente para demostrar que “eso” no es una voz. Sin duda, el descartar un ruido como posible voz le quita bastante encanto o misterio a una psicofonía.
Debería ser suficiente una prueba así. Sin embargo, el parapsicólogo es inasequible al desaliento, y siempre saldrá diciendo algo así como:
“Parece una voz, pero no lo es, lo cual lo hace más paranormal todavía”
Es decir, seguirá fiándose de lo que le dice su sentido del oído.
Apéndice (18/05/06)
Al hilo de la discusión en los comentarios acerca de sintetizadores y distorsiones de voz, he recordado un disco de Jean-Michel Jarre, "Revolutions", donde usaba estos elementos. Así que, he aquí lo que parece un ejemplo perfecto de pareidolia auditiva:


Digo me parece, porque conociendo sólo superficialmente el tema, al escuchar fonema a fonema el sonido desaparecen algunas consonantes de la "palabra". Igualmente, los espectros se ven muy monótonos o artificiales, como si fuera un sintetizador imitando una palabra. Pero expertos habrá que me corrijan si en realidad es una palabra real distorsionada.


21 comentarios:
Estoy -o estaba- preparando una entrada que trata sobre lo mismo, con poca novedad más. En fin, intentaré no repetir todo lo que ya has dicho aquí y aportar algo nuevo (cómo te odio, oh, sí).
Este método para poder diferenciar objetivamente un ruido de la voz humana (yo también me he dedicado a analizar las muestras que hay por internet) tiene el inconveniente de que pocas veces las grabaciones son tan claras como para poder analizarlas, la mayoría tienen un ruido demasiado alto. Pero alguna hay, como has demostrado. Felicidades por la entrada, antes de que se me olvide.
Acabo de asistir a un congreso de especialistas en TCI en el que unos parapsicólogos bastante preparados analizaron una "psicofonía" con métodos de fonética acústica. Digo que estaban "bastante preparados" porque no metieron ningún patinazo en el análisis y lo hicieron todo correctamente (quizás solo me parecieron competentes por compararlos con la tropa lamentable de indocumentados de aquí). Sin embargo, esperaron a las conclusiones para estropearlo todo. Como las pruebas concluían -hasta ahí supieron verlo- que aquello no era un sonido articulado humano (o sea, diagnóstico lógico: ruido), comunicaron entonces al público que aquello "no era una voz emitida por un ser humano". Vamos, el "parece una voz, pero no lo es, lo cual lo hace más paranormal todavía" con que cierras la entrada. Aparte de las ideas preconcebidas, su problema es el de siempre: de nada valen análisis complicadísimos y alta tecnología si el objeto de estudio se obtiene bajo condiciones tan descontroladas.
Saludos
Gracias por un lado, y lo siento por "pisarte" una entrada. De todas formas, nunca viene mal repetir las cosas con otras palabras, para quien no haya entendido algún concepto, y en todo caso, este tema de fonética es tan amplio que creo que también puedes aprovechar para profundizar, sin pararte a explicar conceptos previos que sí estén decentemente explicados (personalmente, no tengo más conocimiento en este tema que lo que he ido leyendo este tiempo por ahí).
Alguna vez he tenido curiosidad por esos congresos de TCI, si harían algo "serio", o si serían las historietas de miedo de siempre. Si por lo menos hasta las conclusiones son serios, algo han avanzado.
Muy buena entrada, Julio.
A esperar la de Gerardo.
Me pregunto si lo escrito aquí puede servir a modo de criterio falsacionista. Me explico (o lo intento):
Si el análisis fonético, en condiciones más o menos ideales, puede determinar si algo es o no una voz, puede falsarse una hipótesis que consistiera en :este sonido es una voz.
La presencia de ruido, al hacer difícil o imposible el análisis, invalida el carácter de "evidencia" del sonido psicofónico.
Por otra parte, el "parece una voz, pero no lo es, lo cual lo hace más paranormal todavía" puede volverse en contra de determinadas interpretaciones de las psicofonías, em parece. Pues si no son voces, no hay "nadie" detrás de ellas.
Visto que ante estos análisis fonéticos los "creyentes" se refugian en "no son voces humanas" yo creo que habría que ir a métodos de teoría de la información. Para casos en que se disponga de gran cantidad de muestras (algún lugar de grabación habitual) puede hacerse un análisis entrópico que quizás permita descartar la transmisión intencionada de información (a un nivel de confianza dado).
Si se pueden descontar interferencias ambientales conocidas (como la corriente de red, creo que algo ya se hizo por aquí) mejor que mejor... realmente no me imagino a estos personajes diciendo "es ruido aleatorio, lo cual lo hace aún más misterioso", aunque nunca se sabe.
bueno, un músico, con ayuda del oído absoluto y un buen órgano melódico o electrónico, es capaz de tocar notas que semejan la voz humana, en un rango limitado. Analizándolas, observaremos que dichas notas vienen acompañadas de sus armónicas. Así, tenemos una voz que no es humana pero que cumple con los criterios de una voz, pero no lo es, lo cual no la hace más paranormal, pero sive para obtener el criterio de falsibilidad.
Observen que dije "en un rango limitado." No creo que haya mucho problema en hacer decir al órgano "mi mamá me mima" pero hacerlo decir "parangaricutirimícuaro" o "supercalifragilisticoespialidoso" es un reto bastante fuerte... aunque no dudo que se pueda hacer.
Asigan,
En principio, con muestras decentes, y un análisis bien hecho (no coger dos espectros y ver a ojo cuanto se parecen) creo que sí podría servir de criterio de falsación, o al menos, como parte de él. Luego queda el problema de saber de donde sale ese ruido o voz. No se por qué será, pero si no es una voz parece una psicofonía pierde su interés paranormal. Creo que la única forma de demostrar que tal ruido no es una psicofonía paranormalísima, es demostrar llegar origen del ruido, lo cual me parece casi imposible.
(...)Pues si no son voces, no hay "nadie" detrás de ellas.
Ese es precisamente lo que a los "expertos" les va a parecer más paranormal todavía: un sonido que no emite ninguna persona, resulta que está diciendo algo que (supuestamente) está rspondiendo una pregunta directa. No se planetarán si la pregunta previa les ha predispuesto a interpretar un ruido como una respuesta más o menos coherente. (que esa es otra "¿Cual es tu nombre? - el de un mensajero" es una respuesta abierta a varias interpretaciones).
Anónimo,
de teoría de información no tengo ni idea, pero desde luego parece una idea interesante. Y no será por cantidad de psicofonías realizadas en sitios como Bélmez, Belchite, y tantos otros. Cuestión de ir recopilando cosas por la red.
Jack
Supongo que siempre es posible "engañar" a un criterio de falsación. Aunque es interesante saber si una voz sintetizada podría distinguirse de una voz real. Yo creo que tiene que haber diferencias notables, no en un fonema concreto, sino en el conjunto de la frase. Un sólo sonido quizás no sea excesivamente complejo, pero hacer una frase entera, con transiciones de fonemas y con entonación me parece más complicado, incluso para "mi mamá me mima".
Veamos...
Por desgracia, las cosas no son tan simples. Aunque el análisis de la estructura de formantes y armónicos de una señal de voz es útil, no es definitivo:
- Los formantes se pueden alterar y aún ser la voz reconocible. Se supone que los filtros que distorsionan la voz tienen efectos de esos.
- Es posible generar voz sin estructura armónica. Es lo que hacemos cuando hablamos en voz baja (como Epi el de Epi y Blas). Aun así, es reconocible.
En general, el sistema auditivo es muy robusto frente a señales de voz distorsionadas... señales que no serían reconocibles a partir de su forma de onda, pero que se siguen identificando como voz correctamente. De hecho, la pareidolia no es más que un efecto colateral de esa potencia del sistema auditivo.
En definitiva: que tu propuesta es un principio interesante; al menos para analizar la naturaleza de las "psicofonías". Es decir, podríamos distinguir entre voces captadas en el proceso de grabación (pongamos, siendo un poco malvados ;-), Iker Jiménez falseando la voz) y ruidos que se interpretan como voces (y que pueden tener orígenes exóticos; desde voces de verdad distorsionadas -a través de una modulación-demodulación AM y un proceso de interferencias- a ruidos aleatorios con una cierta estructura de "formantes"). Pero no sé si podría considerarse la "falsación definitiva"
Evidentemente, si algún investigador de TCI (¿a que suena bonito?) quisiera investigar a fondo los orígenes de las "psicofonías", usaría un método distinto. De entrada, tendría que tener alguna hipótesis acerca del proceso físico que induce las psicofonías en la grabación; y empezar a tirar del hilo a partir de ahí. Y entonces podríamos aplicar este tipo de métodos...
Lo de la teoría de la información, por otro lado, debería funcionar... en teoría. El problema es que, como todo método no lineal, es difícil de controlar (muy "de caja negra"), y no se me ocurre a priori cómo establecer la medida. ¿Alguna idea?
Finalmente, con respecto a lo que dice Jack: es bastante probable que sea posible distinguir una voz sintética de una humana. El problema es que no sé si es fácil hacerlo de forma automática (habría que ponerse a buscar bibliografía). Hasta donde yo tengo entendido, el sistema más potente que tenemos para analizar voz es... nuestro oído (acompañado, si quieres, de unas medidas de osciloscopio...).
Saludos!
h
Evidentemente, una análisis fonético se puede complicar mucho: la respuesta de un micrófono altera el sonido original, ruidos que se cuelen entre medias, sonidos de otros animales (la forma de producirlos no debe ser muy distinta a la humana), susurros... incluso alguna voz perdida de algún "experto en TCI en plena experimentación" que se capte (aunque luego se diga aquello de "estabamos alejados del micro" o "no habló nadie")
Sin duda hay gran cantidad de factores que pueden dificultar un análisis. No es una herramienta definitiva de falsación, pero sí una herramienta útil para ello, y para ayudar a determinar qué se está escuchando.
El problema de saber por qué ha aparecido ese sonido es otro distinto, aunque relacionado. Y por desgracia, creo que es esta última pregunta la que hay que responder sin ningun tipo de duda para convencer a alguien de que una psicofonía no tiene misterio... (y a lo mejor, ni por esas)
Veo que me perdí un buen debate por aquí. Tarde, aporto lo mío.
Un análisis del espectrograma aporta mucha información, es aplicar los métodos del estudio acústico del habla y no es en absoluto un método superficial o incompleto si queremos saber si un sonido es o no una voz humana (siempre dependiendo de la calidad de la grabación). El espectrograma es al fin y al cabo una representación gráfica bastante configurable de la onda, quien tiene los conocimientos necesarios de fonética acústica puede leerlo, y hay más información que la presencia o ausencia de armónicos y formantes.
No creo que con un instrumento musical pueda realizarse una buena imitación de "mi mamá me mima". Puestos a pensar en imitadores, los sintetizadores text to speech ponen el listón mucho más alto, aunque precisamente en cadenas largas es donde se los "caza" antes por su regularidad artificial, o porque no suelen tener sonidos más allá de los 5000 Hz; y eso si solo tenemos el espectrograma, si podemos escuchar la onda ya sabemos que es todavía más fácil. En cuanto a distorsiones de la voz y hablar con susurros: si somos capaces de entender palabras, es porque los sonidos están en las bandas adecuadas, da igual la distorsión o la falta de armónicos, por lo tanto se puede saber si algo es una voz distorsionada o un ruido. Aquí tenéis un espectrograma de banda ancha de la palabra "pala", primero con voz normal y después susurrada (sin sonoridad de las cuerdas vocales). Se observa (porque la forma del resonador es la misma) que, aunque no hay armónicos, el espectro es muy parecido, incluso con unos "formantes" de ruido que se ven afectados de igual manera por la consonante.
El método sirve -como dice Julio, con muestras decentes- para poder diferenciar un ruido que parece una voz de una voz de verdad. Así podemos saber cuándo el sentido del oído del observador está interpretando un ruido como si fuese una voz, o sea, demostrar que tratamos con la pareidolia. Eso me parece lo interesante del análisis. Para utilizarlo como método de demostración de la falsedad de las psicofonías solo sirve para descartar algunas, las que claramente no son voces. Por lo que he ido analizando yo, he observado que en la percepción en muchos casos no es la parte vocálica la que se "recrea" en la pareidolia, sino que sobre unos ruidos en las frecuencias de una vocal y fáciles de interpretar como tal se "añaden" consonantes que no existen, lo que sí es muy claro de ver en el espectrograma, ya que las consonantes también dejan huella.
Es imposible demostrar que todas las psicofonías son falsas, pero mientras no se obtengan en condiciones controladas, tampoco es que haga falta. Por lo de pronto, es interesante para dejar en entredicho el rigor de la investigación en TCI al evidenciar la cantidad de material psicofónico inservible que se incluye entre las grabaciones válidas, vemos que incluso los parapsicólogos más serios aceptan como psicofonía casi todo. Desde luego, lo del "no es una voz pero suena como una voz", es inaceptable.
Conclusión, que me embrollo: lo que de verdad suena como una voz, da un espectrograma igual al de una voz, y lo que no se registra, es que no existe en la onda y se lo está inventando el receptor. Y para esto creo que no hay apelación.
Dejo aquí un enlace a un interesante archivo de audio Ilusiones sonoras.
Pertenece a un espacio de ciencia dentro de un programa de radio de RNE1.
A lo que voy es: ¿qué es una "voz psicofónica" para un "investigador de TCI"? Si asumimos que son voces "de verdad", que quedan registradas en la grabadora por un procedimiento misterioso... pues es evidente que, a poco que tengan cierta relación señal a ruido, tienen que tener estructuras de voz en el espectrograma.
Pero, ¿qué forma de onda tiene una voz "producida por un espíritu extraterrestre"?
Sin ser un experto en la materia, tengo la impresión de que los "investigadores en TCI" están lejos de ofrecer hipótesis plausibles a la pregunta "¿cómo llegó el sonido a la grabadora?".
El argumento que plantea Julio es bueno (aunque insisto en que creo que no es "definitivo"; el oído puede recomponer voz con distorsiones no-lineales que podrían destrozar la forma de onda*). Pero creo que está un paso más allá que lo que se plantea la gente que habla de psicofonías.
Un saludo
h
*Esto es lo que tengo entendido, dicho por gente que trabaja con voz modulada y demodulada; pero yo mismo no he hecho la prueba.
Una falsación de "esto es una psicofonía" (entendiendo psicofonía como una voz grabada por un mecanismo muy misterioso) creo que se podría hacer en dos partes:
- Determinar que lo que se ha escuchado es una voz
- Determinar que ha quedado registrada por un mecanismo misteriosísimo de la muerte (que es la parte con chicha)
Si no pasa el primer test, no tiene sentido pasar al siguiente. En ese sentido es una primera criba, o falsación de "Esto es una psicofonía", pero no una confirmación de que lo sea (además de que las confirmaciones en ciencia no existen)
Si la voz está manipulada, de forma que la voz se reconstruya en el oído como dices, es porque queda información del sonido original, y como tal, debería poder detectarse, no en la forma de onda, sino en el espectro de frecuencias.
Una situación relacionada, aunque distinta a la que sugieres, es el reconocimiento automático de locutores, cuando éstos disimulan o modifican intencionadamente su voz. Según tengo entendido, es posible llegar a identificar al locutor, aunque no se con qué "facilidad" se puede llegar a hacer.
Es decir, si se puede reconocer una voz concreta, o simplemente que un sonido es una voz, es porque hay información que te permite reconstruirla.
(Por cierto , alguna vez probé a modular una voz, multiplicándola por un coseno de frecuencia "f", y la voz salía como robotizada. No la he visto en espectro, pero me imagino que saldrá con mismo patrón de armónicos fn, y formantes, pero a las frecuencias fn±f )
Por cierto, una idea que se me ha ocurrido es pasar psicofonías por algún programa que transcriba de sonido a texto, a ver que sale :). ¿Alguien sabe de algún programa que permita hacerlo?
Regreso yo a mi teorías original del órgano melódico: sí se puede hacer que el órgano "imite" una voz humana sin necesidad de una computadora, porque lo he oído. En algún lado debo tener un cassette con una grabación de mala calidad; es más, en algún lado todavía debe de estar el profesor de música que nos enseñó ese detalle. Deberé buscarlo. Me pregunto si todavía estará vivo...
Pero me despego otra vez del tema. No es una reproducción perfecta. Toma mucho trabajo conseguir la secuencia de notas con la velocidad exacta para pronunciar las palabras, y las notas deben ser muy parecidas en vibrato a la de la voz humana. De hecho, ni siquiera parece una voz masculina, sino femenina. Incluso parece que canta ópera más que hablar. Y es necesario hacerlo en un órgano melódico porque si empleáramos, por ejemplo, un piano, el vibrato es diferente. La "voz" resultante debe oírse como si pasara a través de un pedal Wawa, que es, de hecho, la forma en la que muchos artistas hacen "hablar" a su guitarra...
Ahí radica el secreto de este asunto: como no se puede hacer que la sucesión de notas se corte abruptamente, hay fonemas que no se pueden formar nunca. Y es bastante difícil de lograr.
El mismo efecto se usa en los programas más antiguos de text-to-speech y las tarjetas de sonido MIDI de dos y cuatro operadores: se modula una señal para subir o bajar su frecuencia y que se acerque al sonido que esperamos escuchar. De esta manera, la voz sale "robótica" y los instrumentos suenan "falsos". No hay manera de confundir a la voz de un text-to-speech con un humano real, pero no hay duda de que ahí hay una voz no humana.
Aprovechando esto de la voz no humana, una vez hice yo un experimento con el ViaVoice de IBM y el Naturally Speaking de Dragon. Se suponía que ambos programas convertían la voz en texto, lo que en ese momento me parecía ideal porque hablo más rápido de lo que escribo, a pesar de que escribo bastante rápido. Pasaba más tiempo corrigiendo errores de lo que le dictaba a la computadora, y a veces la computadora entendía algo totalmente diferente a lo que quería pronunciar. Un día intenté hacer el experimento de capturar el audio de un noticiero por la radio. EL programa no entendió mas que cuatro palabras de cada 10, y las entendió mal...
Julio,
Por no dar más vueltas al asunto:
- La estructura de formantes de la voz se debe al aparato fonador humano. La hipótesis "a" que planteas ("Determinar que lo que se ha escuchado es una voz") a lo mejor no sirve para, por ejemplo, "voces de extraterrestres"(*).
- Modificando artificialmente la voz ("hablando con voz rara") uno puede conseguir diferentes formas de distorsión lineal: cambia la forma de la cavidad resonante o incluso modifica la excitación. Eso no afecta significativamente al espectro. Lo que sí afecta al espectro es una distorsión no lineal, que hace que aparezcan nuevos armónicos.
(*)Es decir: ¿cuál es nuestro modelo de psicofonía? ¿Que se produzca como una voz humana o que se oiga como una voz humana? Para lo primero el test de falsación es correcto (con las dificultades de distorsión, interferencia y ruido típicas de estas grabaciones). Para lo segundo... pues depende.
NOTA 1: El modelo de detección de voz que se usa en reconocedores y demás está basado (en principio) en el modelo de producción; ya que se sabe que ambos procesos están relacionados a nivel cognitivo.
NOTA 2: Los mejores sintetizadores de voz usan voz pregrabada y pre-procesada, así que deberían tener formas de onda bastante humanas ;-) El más conocido de los de libre distribución es FESTIVAL
¿Y cómo suena una voz extraterrestre, o de un "ente descarnado"? ¿cómo puedes comparar si un espectro podría corresponder a algo que no conoces? (Además, que tontería, extraterrestres hablando cuando todos sabemos que se comunican telepáticamente desde ganímedes)
:-D
La "gracia" que le encuentran a las psicofonías es que subjetivamente se aprecia que suenan como voz humana. A nadie se le ocurre que se oigan delfines, por ejemplo. Así que no podemos tener otro "modelo de psicofonía" más que "que suene como voz humana", y la única comprobación objetiva posible es comprobar que se ha producido como una voz.
El aspecto general de un fonema emitido por tí o por mí es en rasgos generales igual. Sólo varían los matices del timbre de voz. Puedes coger 100 personas y hacer un "espectro medio" del fonema /a/. Si ahora va un ente descarnado parlanchín del más allá y emite una /a/, deberá contener ese mismo aspecto general, o la misma información. Si no, no es un fonema /a/, sino "otra cosa" que sólo lo parece.
Por ejemplo, las imitaciones de voz que dice Jack con instrumentos musicales, sería interesante ver hasta que punto se parecen a una voz humana. Si esos sonidos pasados por un test de reconocimiento de voz (realizado por un operador, no automático, que parece que no funcionan muy bien todavía) cuelan, entonces sería una invalidación de éste método.
¿Y cómo suena una voz extraterrestre, o de un "ente descarnado"? ¿cómo puedes comparar si un espectro podría corresponder a algo que no conoces?
Pues eso, Julio, pues eso. ¡Que alguien nos lo explique! :-D
Hairanakh: [Pero, ¿qué forma de onda tiene una voz "producida por un espíritu extraterrestre"? ¿Y cómo suena una voz extraterrestre, o de un "ente descarnado"? ¿cómo puedes comparar si un espectro podría corresponder a algo que no conoces?]
La onda, por paranormal que sea, es la misma que una humana o no se puede entender.
Dejemos de lado el origen de la voz por un momento. Tanto si es fuese una grabación del habla humana, como si es un generador de texto a voz, como si es un ente descarnado o un extraterrestre, si lo entendemos como palabras, es debido a que está dentro de los parámetros del habla humana, ya sea porque los entes misteriosos hablen como nosotros o se dignen hablar en nuestro idioma para que los entendamos. Todas estas hipótesis pueden dejarse por el momento, no importan.
Si los sonidos se salen de los parámetros normales, lo que sucede es que no se entienden como habla. Se puede comparar con la percepción del color, que cambia para nosotros según las frecuencias de la luz. Ejemplos del español: una consonante oclusiva sorda altera (tuerce hacia arriba o abajo) los formantes de la vocal que la sigue desplazándolos hacia una explosión en unas frecuencias determinadas, si los cambias, cambia la consonante ("p","t" o "k"), y si te sales, ya no entiendes ninguna de ellas. La vocal "a" se caracteriza por tener sus dos primeros formantes en torno a los 700 y 1500 Hz. y, si cambian, ya no se perciben como esa vocal, sino como otra o un sonido que no es ninguna. Y lo mismo con el resto de sonidos del habla. Dependiendo de la frecuencia en que se encuentran los sonidos, entendemos una cosa u otra, y de ahí no se puedes salir ni un humano ni un extraterrestre ni un ente descarnado. No se puede, porque deja de ser inteligible. Da igual si la onda la crea un aparato fonador humano, la membrana de un altavoz o una energía inexplicable que la graba en un soporte magnético para que le escuchemos después. Por eso podemos saber con total seguridad si un fonema existe en la onda o lo estamos "reconstruyendo" con la pareidolia. Sería distinto si las psicofonías fueran sonidos extraños que hay que descifrar tipo las señales extraterrestres de "Contact", pero por ahora son supuestas cadenas de habla y como tales se pueden analizar.
[Es decir: ¿cuál es nuestro modelo de psicofonía? ¿Que se produzca como una voz humana o que se oiga como una voz humana?]
Que se oiga como una voz humana.
Jack Maybrick: [Regreso yo a mi teorías original del órgano melódico: sí se puede hacer que el órgano "imite" una voz humana sin necesidad de una computadora, porque lo he oído. En algún lado debo tener un cassette con una grabación de mala calidad; es más, en algún lado todavía debe de estar el profesor de música que nos enseñó ese detalle. Deberé buscarlo. Me pregunto si todavía estará vivo...]
Sería muy interesante escucharlo. Yo me imagino que lo que se puede lograr son vocales, diptongos y algunas consonantes sonoras. Pero lo veo necesitado de un poquito de ayuda pareidólica. Que llegue engañar, no sé, no se... ¡Y siento ponerme escéptico!
He encontrado un archivo en el que tenemos una voz sintética muy interesante para explicar lo que decía antes. Un par de datos: el primer formante vocálico en las oclusivas tiende a las frecuencias bajas, y el segundo hacia un punto llamado "locus" que caracteriza cada uno de los fonemas ("p, t, k, b, d, g"). Esta voz sintética reproduce varios sonidos, "ba" (locus sobre los 700 Hz.) "da" (locus sobre los 1800 Hz.) y "ga" (locus sobre los 3000 Hz.), lo interesante es que también reproduce varios sonidos con locus intermedios, que son una estupenda muestra de lo que dije antes ya que podemos comprobar que se hacen extraños al oído y de difícil interpretación. En el espectrograma (para el que he acortado los silencios) vemos cómo el formante va cambiando gradualmente.
Una prueba excelente de lo que trataba yo de explicar (difícil hacerlo sin sonidos, pero la lucha se le hizo).
Si observamos (y escuchamos) bien el audio de Gerardo, vemos que el espectro se reparte a lo largo y alto y ancho, sin espacios intermedios. Eso delata que es sintético. Un sonido natural, aún distorsionado (como el espectrograma de "Revolution" de Jean Michel Jarré, formado con ayuda de un pedal wawa) tiene ciertos espacios en blanco en su espectro, producto de las armónicas producidas por la voz humana.
La voz artificial, en vez de "blancos" en su espectrograma, tiene saturaciones ("negros"). Aquí parece haber una regla. Ojo: sólo parece.
La regla del pulgar es: si el espectrograma tiene blancos, es una voz humana. Si el espectrograma no tiene blancos, es una voz artificial. La disposición de los blancos debe ir de acuerdo a las armónicas humanas: una voz artificial grabada (un sintetizador como los de la AT&T, por ejemplo) reproduce armónicas y la voz se oye muy natural, pero no demasiado: se llegan a notar las diferentes versiones de un mismo fonema y no siempre empatan con el fonema anterior. Hay voces muy entretenidas y naturales, pero nunca he logrado confundir una charla natural y una charla generada. Pero de que podemos emplearlas para hacer unas bonitas psicofonías, podemos...
Y como diría Fríker Jiménez... Tita tutín, tutín, tutín...
PD: Comparen las voces con la frase anterior en el generador de voz... y verán que los acentos regionales y los tonos de voz pueden hacer irreconocible una misma frase...
Jack Maybrick: [Si observamos (y escuchamos) bien el audio de Gerardo, vemos que el espectro se reparte a lo largo y alto y ancho, sin espacios intermedios. Eso delata que es sintético. Un sonido natural, aún distorsionado (como el espectrograma de "Revolution" de Jean Michel Jarré, formado con ayuda de un pedal wawa) tiene ciertos espacios en blanco en su espectro, producto de las armónicas producidas por la voz humana. La voz artificial, en vez de "blancos" en su espectrograma, tiene saturaciones ("negros"). Aquí parece haber una regla. Ojo: sólo parece.]
Creo que no vale como prueba. El que haya espacios en blanco en el espectrograma es causado por el nivel de contraste o sensibilidad a la intensidad que queramos darle a la representación gráfica. Se puede hacer un espectrograma de esa misma voz sintética (la de "ba-da-ga") que se visualice con espacios en blanco; aunque sí que es cierto que es muy tosca en ese sentido.
He estado estos días probando a hacer espectrogramas de sonidos de sintetizadores de voz. Los sonidos de ese "ba-da-ga" son muy poco naturales, así como los generados por "Sodelscot", otro programa que usé, mejor pero muy artificial todavía (apenas hay cambio de tono y la vibración es tan regular que se nota); pero el generador de "Voice Editing", un programa que viene con las grabadoras digitales Panasonic, es muy bueno, en algunas palabras engaña hasta al oído (lo he probado con voluntarios inocentes y no lo notaron). Creo que no podría diferenciarlo de espectrogramas de voz real. Para intentar distinguirlos se puede uno fijar en el tono (perceptible en espectrograma de banda estrecha) y en la vibración demasiado regular de las cuerdas vocales (en los de banda ancha); otra información bastante obvia y sólo aplicable en el sonido original, sin mezclar con otros, será que no existe ningún sonido más que el de la voz, dejando en blanco el resto del espectro, al no ser una grabación sino un archivo artificial; esto es raro excepto en grabación en estudio.
Julio: [Al hilo de la discusión en los comentarios acerca de sintetizadores y distorsiones de voz, he recordado un disco de Jean-Michel Jarre, "Revolutions", donde usaba estos elementos. Así que, he aquí lo que parece un ejemplo perfecto de pareidolia auditiva.]
A mí en cambio no me parece que sea una pareidolia, ya que la presencia de sonidos "en su sitio" se observa en el espectrograma, sí que hay ciertas frecuencias intensificadas lo suficiente como para entender la palabra (en el caso de las vocales, vemos más cambios en los primeros formantes que en los segundos, pero los hay). Quizás lo veo mejor porque he usado "Spectrogram" con la muestra wav que dejas y podido configurar más la representación del sonido (creo que tú has usado el "Speech Feeling System" menos configurable en esto). Yo creo que debemos hablar de pareidolia cuando el oyente crea escuchar sonidos que en realidad no existen; es decir, que alguien escuche por ejemplo una "s" pudiéndose comprobar en el espectrograma que no hay ningún ruido en las frecuencias normales de la "s". En este sonido, comparando con lo que puedo trasladar al inglés de fonética del español, todo parece en su sitio, además, se entiende bien, sin "aguzar el oído".
[Digo me parece, porque conociendo sólo superficialmente el tema, al escuchar fonema a fonema el sonido desaparecen algunas consonantes de la "palabra". Igualmente, los espectros se ven muy monótonos o artificiales, como si fuera un sintetizador imitando una palabra. Pero expertos habrá que me corrijan si en realidad es una palabra real distorsionada.]
No sé si es una voz distorsionada o sintetizada y me parece que eso será más fácil saberlo por un fanático de Jarre que por un espectrograma. A primera vista tiene una cosa rara que se ve mucho mejor en tu espectrograma: sonoridad, vibración vocálica, durante la sílaba "tion", que creo debería ser una fricativa sorda /ʃ/ (según el Cambridge Dictionary) y esto apunta al sintetizador más que a la distorsión, pero para saberlo con seguridad, mejor esperar al experto en Jarre.
Una inexactitud en el párrafo final de lo anterior: la falta de sonoridad debe ser solo en la realización del fonema /ʃ/ de la sílaba "tion", claro, y no en toda la sílaba de la que forma parte.
Publicar un comentario